Keywords:
Gemini: A Family Of Highly Capable Multimodal Models, Gemini, Google, paper, LLM, AI, fulltext, web, html, pdf, markdown, translation, translate, Chinese, multimodal, model
谷歌,双子座,技术报告,介绍、双子座: 一组功能强大的多模态模型,论文,全文,网页版,翻译,多模态,模型,中文,汉语
重要问题梳理
Q1:普通用户现在能体验到 Gemini 模型吗?
A:Gemini 不是单个模型,而是一组模型,分为 Nano、Pro、Ultra 三款,相当于中杯、大杯、超大杯。Ultra 被报道为全面超过 GPT-4,Pro 被报道为超过 GPT-3.5。目前 Pro 版本可以在 Bard 上免费体验,但 Ultra 还不能体验,大概到明年初才能付费体验。
Q2:开发者现在能用到 Gemini 的 API 吗?
A:据说从 12.13 开始,可以用 Pro 的 API。但 Ultra 的 API 什么时候开放还不确定。
Q3:谷歌有一个实时视频理解与互动的宣传视频(https://youtu.be/UIZAiXYceBI,国内可查看这里)看上去很牛,是真的还是营销?
A:有一定的营销成分在里面,实际实验时,是用图片和文字作为输入,文字作为输出的。实际延时比视频里展示的要长。可以参考谷歌后续的解释:https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html
Q4:Ultra 究竟有没有视频理解能力?
A:从模型输入来看,是支持视频输入的。但实际处理时,是从视频中抽取了等间距的 16 帧画面做进一步理解,所以简单简短的视频是可以解决的,更复杂更长的视频肯定不行了。
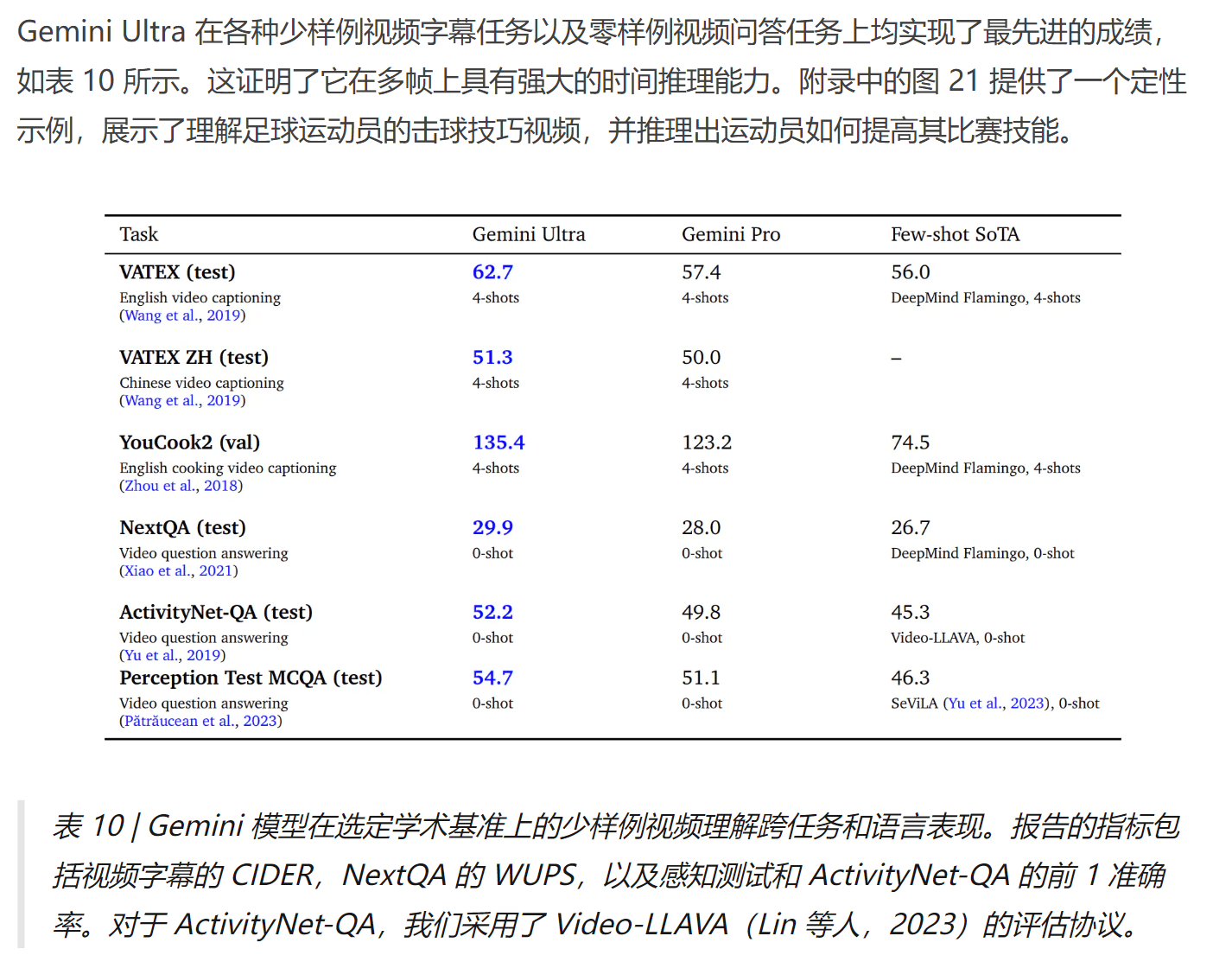
Q5:Ultra 的视频理解能力如何?
从学术测评结果来看,已经实现了最先进的水平,但没有和 GPT-4V 来比。从图像理解推测,应该和 GPT-4V 能力接近。
Q6:Ultra 的图片理解能力,和 GPT-4V 相比怎么样?
仅从图片识别和对图片细节的理解方面来看,Ultra 的能力显著优于 GPT-4V 。在9项学术测评标准中,全部取得最好成绩,全面优于 GPT-4V (眼神更好)。
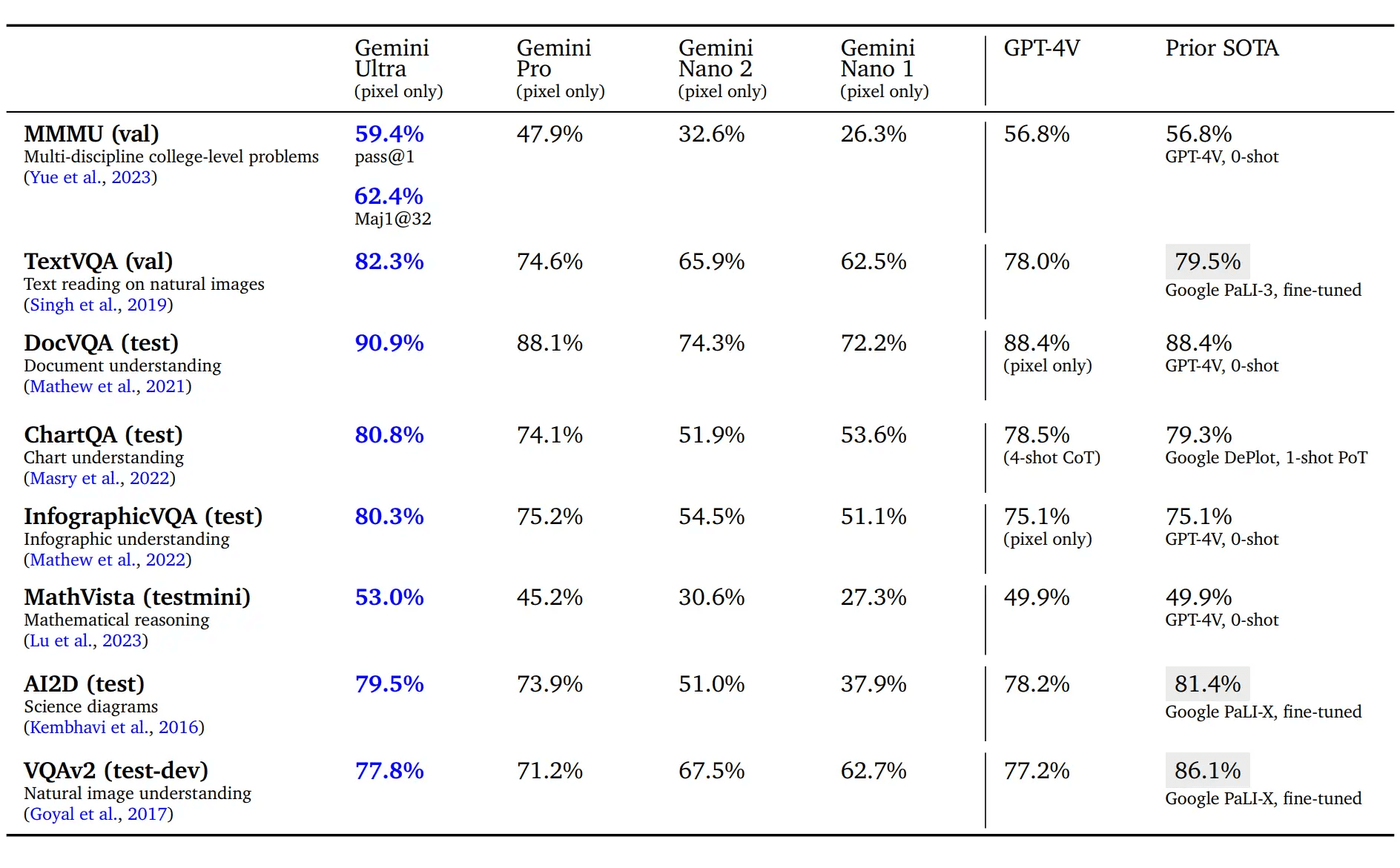
但如果将图片作为考试题目,需要进一步的推理和其他知识来解题,则和 GPT-4V 不相上下(智商差不多)。
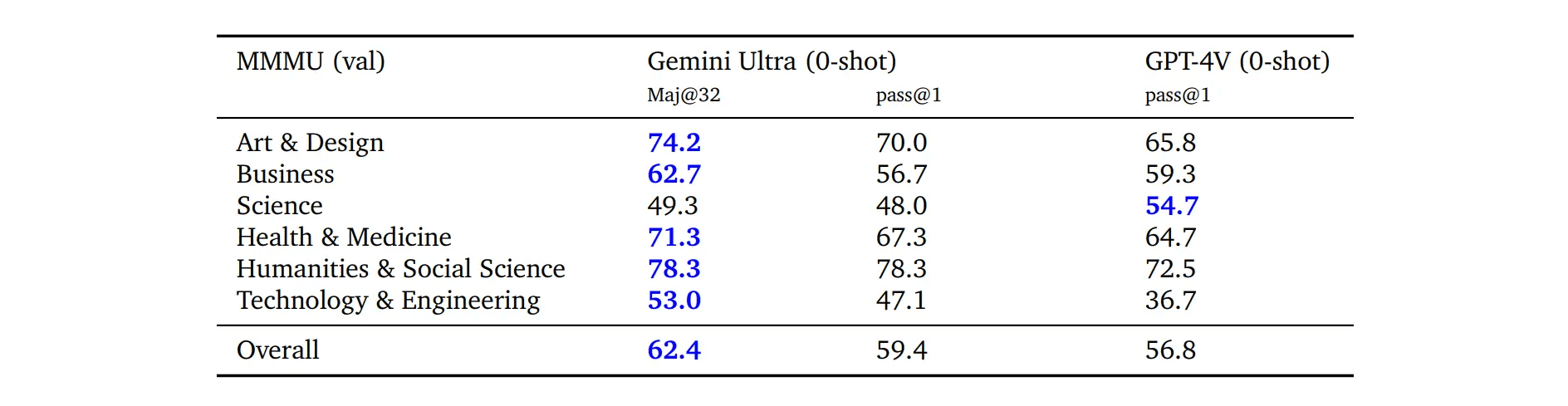
在最新的 MMMU 基准测试(多模态,需要大学水平知识和深入推理的多学科图像问题)中,和 GPT-4V 相比略有提升。
- 直接对比,Ultra 为 59.4 分, GPT-4V 为 56.8 分,在科学上明显更差,商业方面略差,艺术、健康、医疗、人文社科、技术工程领域更好。
- 若使用“不确定性引导思维链”方法,可提升至 62.4 分,除科学依然落后于 GPT-4,其他学科都更优。
Q7:Ultra 对图片中的中文理解能力如何?和 GPT-4V 相比怎么样?
都很烂。多语言图像理解上,Ultra 英语 86.4 分,中文 33.3 分,中文差很多。没有对比 GPT-4V 的结果,不过 GPT-4V 的中文识别能力也不可用。
Q8:听说 Ultra 考试能超过人类了?是真的吗?
是的,在 MMLU 考试基准测试中,Ultra 首次达到了人类专家的水平。之前人类专家得分是 89.8%,GPT-4 得分 87.3%,Ultra 得分 90.0%。但达到该成绩的成本也较高,不是答一次就直接得到了这个成绩,而是采用了“不确定性引导思维链”方法。
“不确定性引导思维链”方法是这样的:该模型生成了 k=32 个样本的思维链,如果存在高于预设阈值的一致性,就会选择这个答案,否则它会回退到基于最大可能性选择的贪心样本,而不使用思维链。
通俗来说就是,连续考 32 次,比较 32 次的结果,如果答案相对集中有一致性,那么选集中的那个答案。如果答案五花八门,选最有信心的那个答案。
如果只是简单一次回答,则 Ultra 略低于 GPT-4,显著低于人类专家水平。(Ultra 是 84.0%,GPT-4 是 84.2%)。
Q9:Ultra 和 GPT-4 的推理能力,究竟谁更好?
从测评结果来看,谷歌基本都采用了思维链技术,或者多示例的技术,才能略由于 GPT-4。如果 Ultra 好很多,那么不必搞这么复杂的方法就能超越;如果 Ultra 差很多,搞各种技巧估计也很难超越。由此推测 Ultra 和 GPT-4 的推理能力可能接近,用户体验不到太大差别。
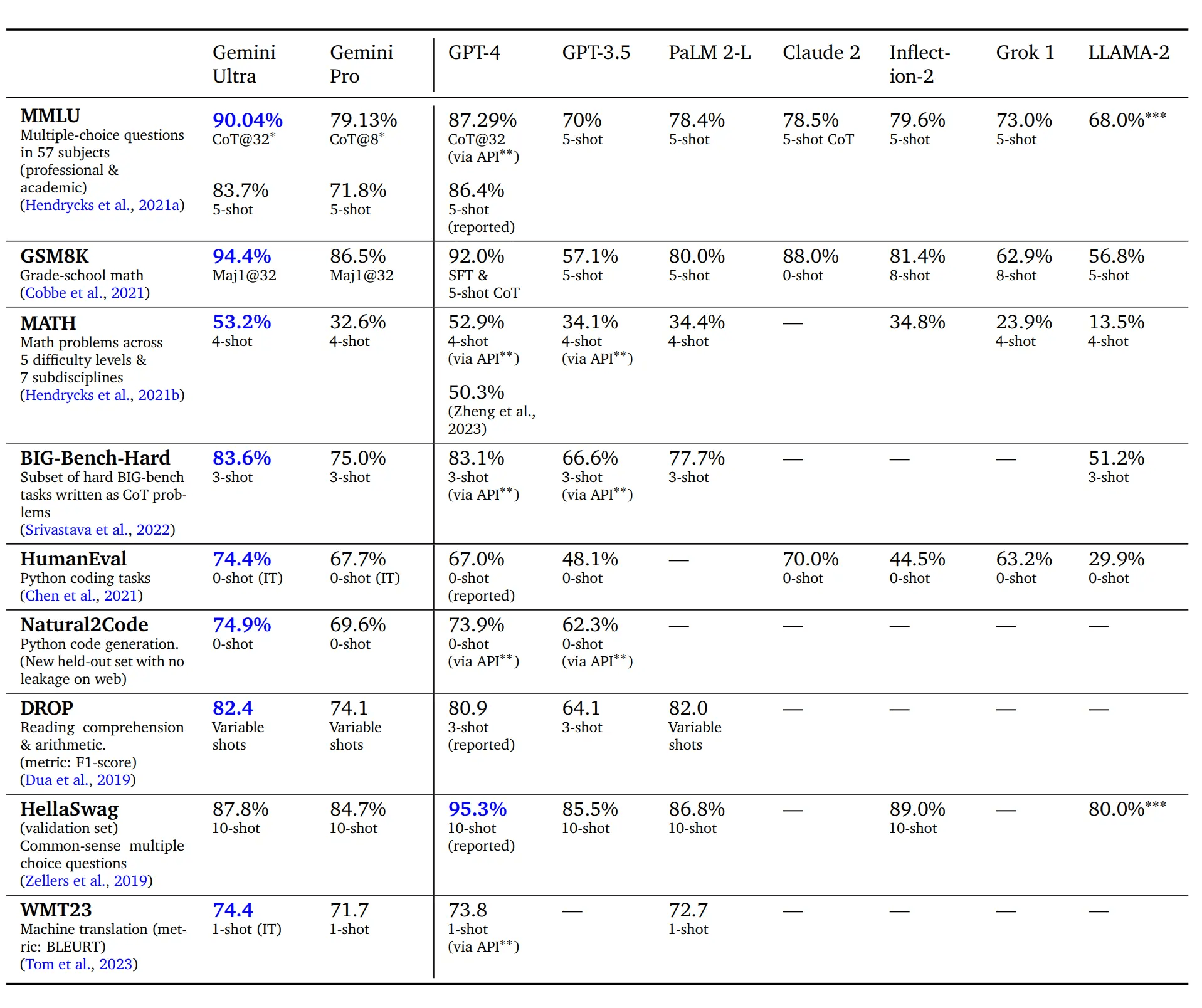
Q10:Ultra 和 GPT-4 的编程能力谁更好?
Ultra 可能略优于 GPT-4。
在函数描述转 Python 方面,在 HumanEval 测评上, 在无示例情况下,Ultra 显著高于 GPT-4(Ultra 为 74.4%,GPT-4 为 67.0%)。但在另一个保留测评集 Natural2Code 上,Ultra 只比 GPT-4 高一点(Ultra 为 74.9%,GPT-4 为 73.9%)。二者差异可能是 HumanEval 的答案泄露,被 Ultra 提前训练到导致的。
在编程竞赛方面:AlphaCode 2 在 Codeforces 竞赛编程平台上的排名进入了前 15%,相比其前身(排名前 50%)有了显著的提升,但没有和 GPT-4 对比。
Q11:Gemini 的长下文有多长?和 GPT-4 相比,有优势吗?
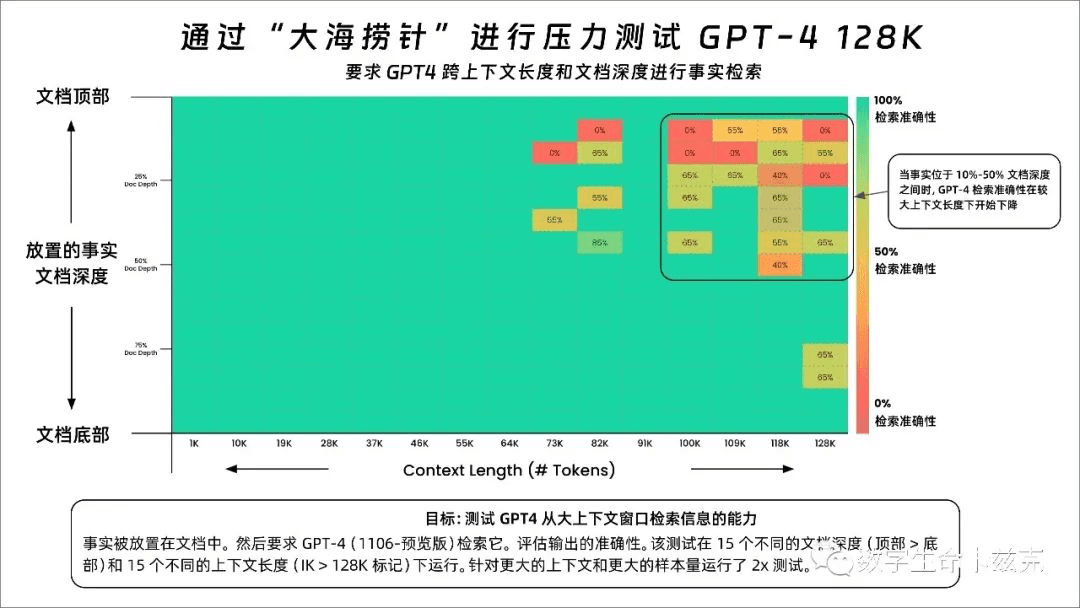
有较大劣势。Nano、Pro、Ultra 的上下文长度相同,都是 32k,和 GPT-4 的 128k 相比,差距较大。在长上下文的准确率方面,Ultra 模型在整个 32K 上下文长度内以 98% 的准确率检索到正确值,还是很高的。当然,对 GPT-4 来说,前 73K 的准确率也很高。如下图所示:原推文:https://x.com/GregKamradt/status/1722386725635580292?s=20
Q12:Ultra 的中文能力如何?
无法给出明确结论。从以下信息推测和 GPT-4 的中文能力接近。
从多语言翻译来看,英译外取得了最高分,超过 GPT-4;但外译英还是 GPT-4 最高。结果基于单示例提示,而非直接翻译。
从多语言数学和摘要来看,在 8 示例的提示下,可以在多语言数学基准测试 MGSM 中超过 GPT-4,达到最好成绩。
然而报告中都只是笼统说了外语能力,没有单独针对中文进行说明,所以只能给出推测。
Q13:Ultra 会比 GPT-4 更可控听话、减少幻觉吗?
无法给出明确结论。在遵循指令、创造性写作、多模态理解、长上下文理解和安全性等人类偏好评估中,Ultra 只对比了 PaLM 2,没对比 GPT-4。在通过监督式微调,促进模型降低幻觉方面,只对比了采取措施前后的提升,没有对比 GPT-4。本着没有明确说更好,就是更差的原则,Ultra 不会比 GPT-4 更可控听话、减少幻觉。
Q14:Gemini 音频理解能力如何,和 Whisper 相比怎么样?
明显提升。Pro 的性能已经比 Whisper 的效果显著好了,Nano-1 的性能也略优于 Whisper,都支持普通话。Ultra 肯定更好。
Q15:关于 Pro 和 Nano,还有哪些信息值得关注?
Pro 的训练相当高效,能够在几周内完成预训练。
Nano 实际有两个版本, 一个 1.8B(Nano-1)一个 3.25B(Nano-2)。他们都是从更大的 Gemini 模型中蒸馏得来,实现了 4 位量化,在同类产品中提供了最佳性能。语音识别性能超过 Whisper。
Q16:综合评价一下 Ultra,它对 GPT-4 会产生怎样的影响?
虽然关于 Gemini Ultra 营销造假的评论不绝于耳,但我对 Gemini Ultra 的整体评价还是非常积极的。即使它不能算作全面超越 GPT-4 的模型,那也已经是在各方面都能和 GPT-4 不相上下的模型了。
它有一些明显的优势:走通了原生的多模态模型这条路,为未来模型继续扩张打下基础。显著提升了图片细节理解能力、显著提升了音频理解能力(可以区分音调,区分不同人的音色),大概率更好的编程能力,具备更复杂视频理解能力的潜力。
明显的劣势仅为上下文长度。
这意味着用户很容易从 GPT-4 迁移到 Gemini 去。在对上下文长度要求不高的场景,只要价格,或者响应速度能比 GPT-4 更优,Gemini 就能对 GPT-4 施压极大压力,形成双巨头的局面。后续就看 OpenAI 的下一代模型是否能及时跟上,保持第 1 的位置了。
笔记
- 按尺寸分类有三种不同规模:Ultra、Pro 和 Nano
- 都是原生的多模态模型
- 输入:支持交错的文字、音频、图片、视频(视频实际是从中抽 16 帧)
- 输出:文字、图片

- Ultra
- 参数量:具体未披露,只知道相比 PaLM-2,规模有显著提升
- 上下文长度:32k
- 数据集
- 在一个包含多模态和多语言的数据集上进行训练,包括网页文档、书籍、代码、图像、音频和视频
- 使用 SentencePiece 分词器
- 应用了质量过滤器,进行了安全过滤,以排除有害内容
- 分阶段调整训练,以改变数据组合——在训练后期增加与特定领域相关数据的比重
- 训练:利用 TPUv5e 和 TPUv4 训练
- 评估
- 联合训练能够产生在各个域都表现出超过当前单一域的模型的性能
- 取得 SOTA 的指标:30/32
- 文本:10/12
- 图像:9/9
- 视频理解:6/6
- 语音识别与翻译:5/5
- 纯文本推理
-
总体评价:分数上略高于 GPT-4,但多数需要在提示中加入示例才能达到效果,实际体验可能和 GPT-4 差别不大
-
在 MMLU 考试基准测试中首次达到了人类专家的水平,其得分超过 90%:但方法是“不确定性引导思维链”。该模型生成了 k=32 个样本的思维链,如果存在高于预设阈值的一致性,就会选择这个答案,否则它会回退到基于最大可能性选择的贪心样本,而不使用思维链。如果不用该方法,该测评上性能略低于 GPT-4

-
编程:
- 在函数描述转 Python 方面,在 HumanEval 测评上, 在无示例情况下,Ultra 显著高于GPT-4(Ultra 为 74.4%,GPT-4 为 67.0%)
- 在编程竞赛方面:AlphaCode 2 在 Codeforces 竞赛编程平台上的排名进入了前 15%,相比其前身(排名前 50%)有了显著的提升
-
多语言
- 翻译:英译外最高分,外译英还是 GPT4 最高。结果基于单示例提示
- 多语言推理:在多语言的数学基准测试 MGSM 中,通过 8 示例提示,表现可超过 GPT-4
-
长上下文:Ultra 模型在整个 32K 上下文长度内以 98% 的准确率检索到正确值
-
人类偏好评估(遵循指令、创造性写作、多模态理解、长上下文理解和安全性):只对比了 PaLM 2,没和 GPT-4 对比
-
- 多模态
-
在最新的 MMMU 基准测试(多模态,需要大学水平知识和深入推理的多学科图像问题)中,和 GPT-4V 相比略有提升
- 直接对比,Ultra 为59.4分, GPT-4V 为 56.8 分,在科学上明显更差,商业方面略差,艺术、健康、医疗、人文社科、技术工程领域更好
- 若使用“不确定性引导思维链”方法,可提升至 62.4 分,除科学依然落后于 GPT-4,其他学科都更优
-
图像细节理解相比 GPT-4V 提升很明显,且无需思维链方法
-
多语言图像理解上,英语 86.4 分,中文 33.3 分,差距很大。没有对比 GPT-4V 的结果,不过 GPT-4V 的中文识别能力也不可用
-
视频理解:对于每项视频任务,从每个视频剪辑中抽取 16 帧等间隔帧,输入至 Gemini 模型。没有和 GPT-4V 对比
-
图像生成:展现了简单的毛绒玩具照片的图像,没有进一步分析。侧重展示的是理解能力,而非生成能力。
-
音频理解:Pro 的性能已经比 Whisper 的效果显著好了,Nano-1 的性能也略优于 Whisper,支持普通话
-
- 降低幻觉:通过策划专门的监督式微调数据集和进行 RLHF 来促进 Gemini 模型展现这些期望行为:
- 归因:若指示要求生成的响应完全基于提示中给出的上下文,Gemini 应产生最忠实于上下文的响应
- 闭卷响应生成:如果提出一个寻求事实的提示,而没有给定任何来源,Gemini 不应产生错误的幻觉信息
- 规避:如果给出的输入提示是“无法回答的”,Gemini 不应产生幻觉。相反,它应该通过规避来表示无法提供答案。
- 结果:事实性测试集中的不准确率减少了一半,在归因测试集中的归因准确率提高了 50%,在提供的规避测试集任务中,成功规避的比率从 0% 提高到了 70%。但没有和 GPT-4 比较
- Pro
- 能够在几周内完成预训练
- Nano
- 两个版本的 Nano,分别拥有 1.8B(Nano-1)和 3.25B(Nano-2)参数
- 通过从更大的 Gemini 模型中蒸馏得来,实现了 4 位量化,在同类产品中提供了最佳性能。语音识别性能超过 Whisper