Relevant Documents:
Keywords:
Gemini: A Family Of Highly Capable Multimodal Models, Gemini, Google, paper, LLM, AI, fulltext, web, html, pdf, markdown, translation, translate, Chinese, multimodal, model
谷歌,双子座,技术报告,介绍、双子座: 一组功能强大的多模态模型,论文,全文,网页版,翻译,多模态,模型,中文,汉语
In-depth Analysis of Key Issues
Q1: Is the Gemini model currently accessible to general users?
A: Gemini consists of a suite of models, including Nano, Pro, and Ultra versions, analogous to medium, large, and extra-large sizes. Ultra is acclaimed to outperform GPT-4, while Pro surpasses GPT-3.5. The Pro version is currently available for trials on Bard for free, but Ultra remains inaccessible, likely becoming available for paid trials early next year.
Q2: Are Gemini's APIs available for developers now?
A: As of December 13th, Pro's API has been made accessible. However, the release date for Ultra's API remains uncertain.
Q3: Google's promotional video on real-time video understanding and interaction (https://youtu.be/UIZAiXYceBI, also viewable here in China) is quite impressive. Is it genuinely effective or merely a marketing tactic?
A: The video does incorporate a marketing angle. In reality, the experiments use images and text as inputs with textual outputs, experiencing longer delays than depicted in the video. For more accurate insights, refer to Google's follow-up explanation: https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html
Q4: Does Ultra truly possess video understanding capabilities?
A: Ultra is designed to accept video inputs. However, in practice, it processes by extracting 16 evenly spaced frames from videos, indicating that while it can handle straightforward, brief videos, it struggles with more complex, extended footage.
Q5: How effective is Ultra's video understanding?
Judging from academic assessments, Ultra has reached cutting-edge levels in this domain, though it hasn't been directly compared to GPT-4V. Its image understanding abilities suggest a performance level close to GPT-4V.

Q6: Comparing Ultra's Image Understanding Capabilities with GPT-4V
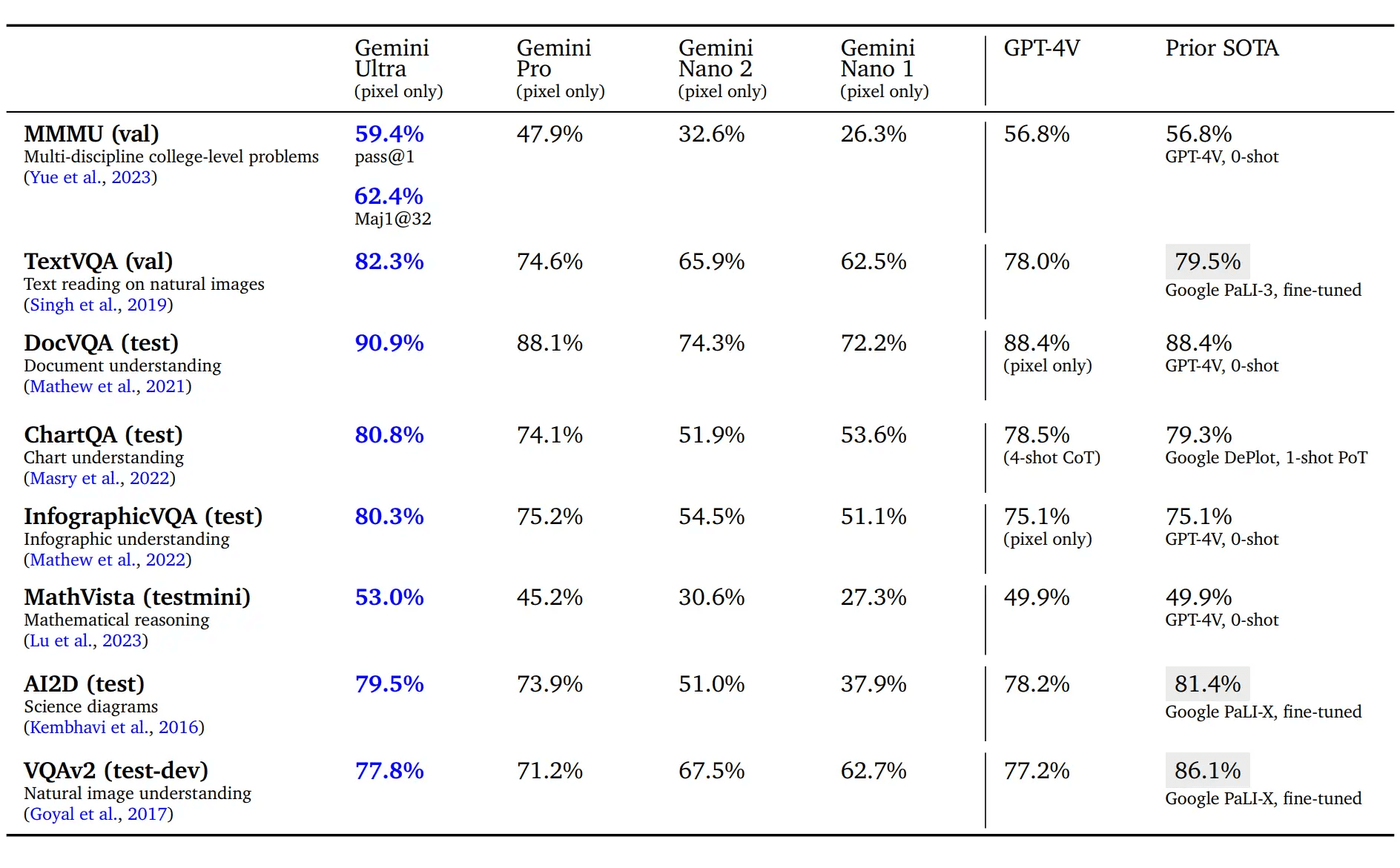
Ultra significantly surpasses GPT-4V in both image recognition and detailed image analysis, achieving top marks in all 9 academic benchmarks, indicating a clear edge in detail perception.
However, when images serve as complex problem-solving questions requiring additional reasoning and knowledge, Ultra matches GPT-4V, indicating a similar level of analytical intelligence.
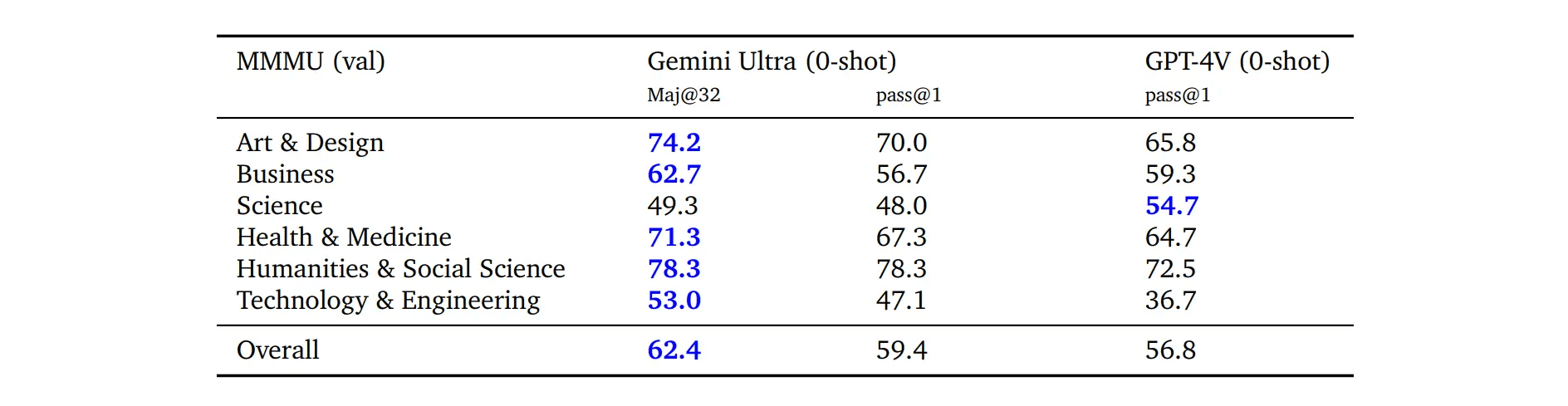
In the latest MMMU benchmark - a test that challenges multimodal understanding and requires extensive college-level knowledge and reasoning - Ultra slightly edges out GPT-4V:
- In direct comparison, Ultra scores 59.4 to GPT-4V's 56.8. While Ultra lags in scientific accuracy and slightly underperforms in business, it excels in the arts, health, medicine, humanities, social sciences, and technology engineering.
- Employing the "uncertainty-routed chain-of-thought" method, Ultra's performance can be boosted to 62.4, surpassing GPT-4 in most disciplines except for science.
Q7: Ultra's Proficiency in Understanding Chinese in Images Compared to GPT-4V
Both models demonstrate limited capabilities in multi-language image understanding. Ultra scores 86.4 in English but only 33.3 in Chinese, highlighting a substantial proficiency gap. While no direct comparison with GPT-4V's Chinese understanding is available, GPT-4V's performance in this area is also not notably effective.
Q8: Can Ultra Truly Surpass Human Performance in Exams?
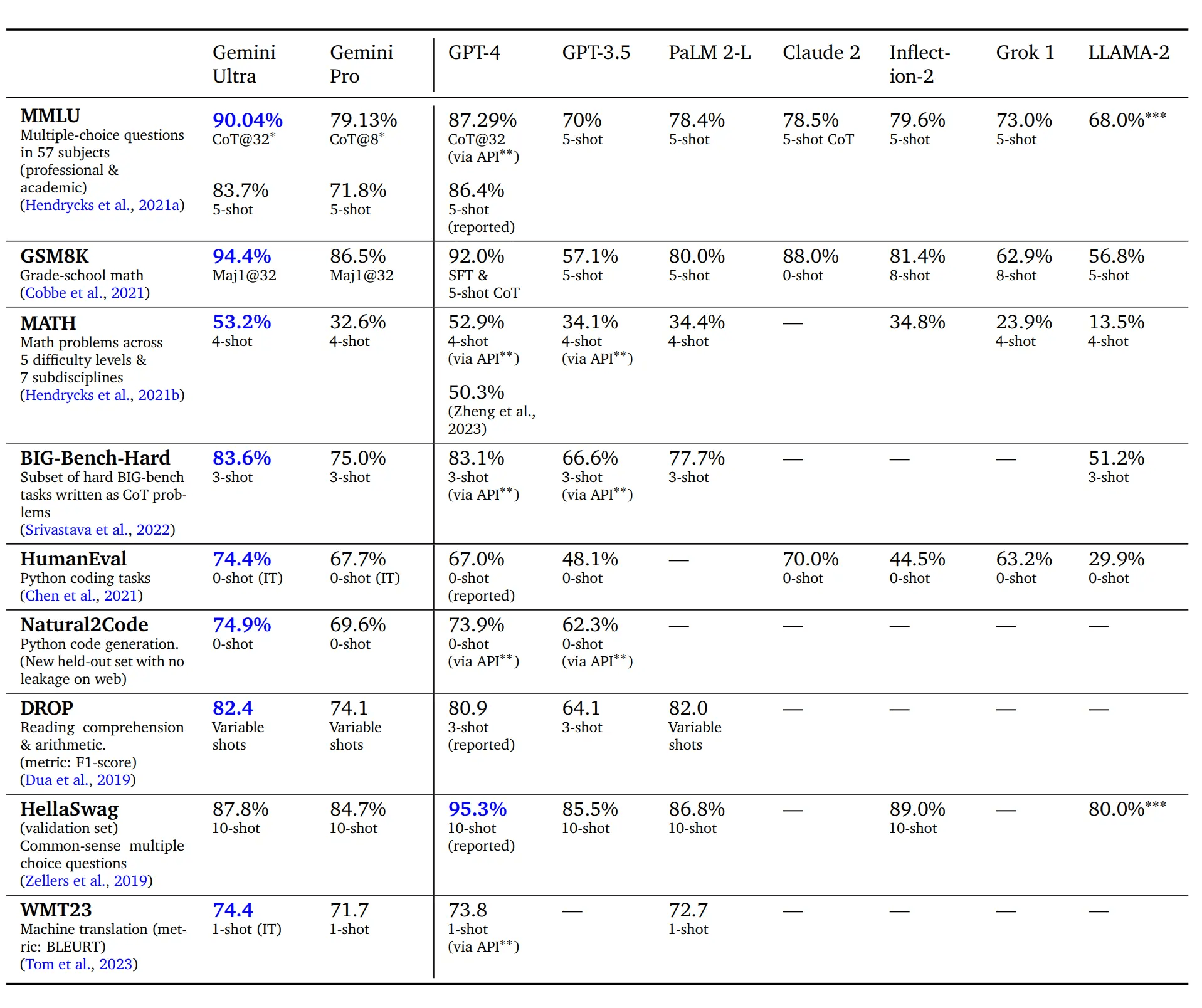
Indeed, Ultra has reached human expert levels in the MMLU exam benchmarks, surpassing previous human expert scores of 89.8% and GPT-4's 87.3% with a score of 90.0%. However, this achievement comes at a cost of complexity and multiple attempts, utilizing the "uncertainty-routed chain-of-thought" method.
This method involves generating 32 different chain of thought (k=32 samples). If a high level of consistency is observed above a predetermined threshold, that answer is selected. Otherwise, the model defaults to a greedily chosen sample based on maximum likelihood, not relying on the thought chain.
Put simply, it's akin to taking the test 32 times, comparing results, and choosing the most consistent answer. If answers vary widely, the most confident one is selected.
In a straightforward, single-response format, Ultra scores just below GPT-4 and significantly below human expert levels, with Ultra at 84.0% and GPT-4 at 84.2%.
Q9: Ultra vs. GPT-4: A Comparison of Reasoning Abilities
Analysis of the results suggests that Ultra's reasoning capabilities are comparable to GPT-4. Google's reliance on thought chain technology or multiple-example approaches to marginally outperform GPT-4 implies that a significant gap in reasoning ability does not exist between the two models.
Q10: Ultra vs. GPT-4 in Programming Skills
Ultra appears to have a slight edge over GPT-4 in programming.
In the domain of translating function descriptions into Python, Ultra outshines GPT-4 in the HumanEval benchmark without examples (74.4% for Ultra vs. 67.0% for GPT-4). On the Natural2Code benchmark, however, Ultra's lead is minimal (74.9% for Ultra vs. 73.9% for GPT-4), potentially due to early exposure of Ultra to HumanEval's answers.
In competitive programming, AlphaCode 2 achieved a top 15% ranking on the Codeforces platform, marking a notable improvement over its predecessor (previously in the top 50%). However, a direct comparison with GPT-4 is not provided.
Q11: Context Length of Gemini Models Compared to GPT-4
Gemini models, including Nano, Pro, and Ultra, are at a notable disadvantage with a context length of 32k, significantly shorter than GPT-4's 128k. Despite this, Ultra maintains a high accuracy rate of 98% in retrieving correct values across its 32k context, demonstrating robust performance. In contrast, GPT-4 retains high accuracy within the first 73k of context, as illustrated in the following tweet: https://x.com/GregKamradt/status/1722386725635580292?s=20

Q12: Ultra's Proficiency in the Chinese Language
Drawing a definitive conclusion on Ultra's Chinese language capabilities is challenging. Indicators suggest its performance is on par with GPT-4. In multilingual translation, Ultra excels in translating from English to other languages, surpassing GPT-4. However, in translations from other languages to English, GPT-4 remains superior. These assessments are based on single-example prompts rather than direct translations.
In multilingual mathematics and summarization, Ultra surpasses GPT-4 in the MGSM benchmark with the aid of 8-example prompts, achieving top marks.
Nonetheless, the report broadly discusses foreign language capabilities without specifically addressing Chinese, leading to these inferences rather than concrete conclusions.
Q13: Ultra's Controllability and Susceptibility to Hallucinations Compared to GPT-4
It's difficult to assert whether Ultra is more controllable or less prone to hallucinations than GPT-4. In evaluations focusing on human preferences, such as adherence to instructions, creative writing, multimodal understanding, long context understanding, and safety, Ultra only benchmarks itself against PaLM 2, not GPT-4. Moreover, in its efforts to minimize hallucinations through supervised fine-tuning, comparisons are made against its previous iterations, not directly with GPT-4. Based on the principle that an unasserted superiority implies inferiority, it's likely that Ultra is not more controllable or less hallucination-prone than GPT-4.
Q14: How Does Gemini's Audio Understanding Capabilities Compare to Whisper?
Gemini showcases a distinct improvement in audio understanding over Whisper. Pro's performance notably exceeds Whisper, and even the Nano-1 model slightly outperforms it, both supporting Mandarin. Ultra is expected to be even more advanced in this regard.
Q15: Additional Insights on Pro and Nano Models
The Pro model stands out for its remarkably efficient training, capable of completing its pre-training phase within weeks.
Regarding the Nano models, there are two versions: Nano-1 with 1.8 billion parameters and Nano-2 with 3.25 billion. Both models are distilled from larger Gemini models and feature 4-bit quantization, setting the benchmark for performance in their class. Their speech recognition capabilities notably surpass those of Whisper.
Q16: Ultra's Overall Evaluation and Its Impact on GPT-4
Despite criticisms regarding Gemini Ultra's marketing strategies, the model garners a positive overall assessment. While it may not decisively surpass GPT-4, it competes closely in various domains.
Key advantages of Ultra include its pioneering role in native multimodal modeling, significant improvements in image detail comprehension and audio understanding (distinguishing pitches and voice tones), potentially superior programming skills, and the capability for more intricate video interpretation.
Its primary disadvantage lies in shorter context length, but this does not significantly diminish its competitiveness. Given the right pricing and response time advantages, Gemini could easily tempt users away from GPT-4, potentially leading to a competitive duopoly in the market. The onus is now on OpenAI to respond with its next-generation models to maintain its market leadership.
Insights
-
Gemini features three distinct models: Ultra, Pro, and Nano, each varying in size and capability.
- All are inherently multimodal in nature.
- Input Capabilities: These models adeptly handle a mix of text, audio, images, and videos. For videos, they process by extracting 16 key frames.
- Output Formats: Capable of generating text and images.

-
Ultra Model
- Parameters: The exact number remains undisclosed but is significantly larger than its predecessor, PaLM-2.
- Context Length: Capped at 32k tokens.
- Data Training: Trained on a diverse dataset comprising multimodal and multilingual elements, including web pages, books, code, images, audio, and video.
- Employs the SentencePiece tokenizer for efficient text processing.
- Includes rigorous quality and safety filters to eliminate harmful content.
- Training phases were tailored to progressively focus more on domain-specific data.
- Training Hardware: Utilized advanced TPUs, specifically TPUv5e and TPUv4.
- Performance Evaluation
-
Demonstrated superiority across various domains, exceeding the capabilities of existing models focused on single domains.
-
Achieved state-of-the-art (SOTA) results in 30 out of 32 tested areas:
- Textual Analysis: 10 out of 12
- Image Processing: 9 out of 9
- Video Understanding: 6 out of 6
- Voice Recognition and Translation: 5 out of 5
-
Textual Reasoning
-
Overall, Ultra marginally outperforms GPT-4, but this often requires including examples in the prompts. The real-world user experience might not significantly differ from that of GPT-4.
-
Scored over 90% in the MMLU exam benchmarks, matching human expert levels for the first time. This was achieved using the "uncertainty-routed chain-of-thought" method, generating multiple chain of thought and selecting the most consistent response. Without this method, its performance slightly trails behind GPT-4.

-
Programming Capabilities:
- Outperforms GPT-4 in converting function descriptions to Python in the HumanEval benchmark (74.4% for Ultra, 67.0% for GPT-4).
- AlphaCode 2 ranks in the top 15% on the Codeforces competitive programming platform, a significant leap from its earlier ranking.
-
Multilingual Competence:
- Translation: Tops in translating from English to other languages, surpassing GPT-4. For translations from other languages to English, GPT-4 leads.
- In the MGSM multilingual math benchmark, Ultra exceeds GPT-4 with the help of example-based prompts.
-
Long Context Handling: Maintains a 98% accuracy in retrieving correct values across its entire 32k context.
-
Human Preference Evaluation: Compared only to PaLM 2 in areas like instruction adherence, creative writing, multimodal understanding, long context understanding, and safety, not benchmarked against GPT-4.
-
-
Multimodal Capabilities:
-
Shows slight improvement over GPT-4V in the latest MMMU benchmark, which tests deep reasoning on multidisciplinary image problems.
- Direct comparison: Scores 59.4 for Ultra vs. 56.8 for GPT-4V. While lagging in scientific accuracy, Ultra excels in arts, health, medicine, humanities, social sciences, and technology engineering.
- Using the "uncertainty-routed chain-of-thought" method boosts its score to 62.4, outperforming GPT-4 in all subjects except science.
-
Image Detail Understanding: Ultra demonstrates a notable leap over GPT-4V in the realm of image detail comprehension. Its ability to discern intricate details in images is markedly superior, achieving this heightened level of understanding without relying on the "uncertainty-routed chain-of-thought" method.
-
Multilingual Image Understanding: Ultra scores significantly higher in English (86.4) compared to Chinese (33.3), highlighting a notable gap in its Chinese language understanding. No direct comparison is available with GPT-4V, but GPT-4V's Chinese recognition capabilities are also not deemed highly effective.
-
Video Understanding: Ultra processes video inputs by extracting 16 frames from each clip for analysis. Its performance in this domain hasn't been directly compared with GPT-4V.
-
Image Generation: Displays a focus on basic image generation capabilities, such as creating images of plush toys, but lacks a deeper analysis of this feature. The emphasis appears to be more on comprehension rather than generation skills.
-
Audio Understanding: The Pro variant outshines Whisper significantly in audio processing, with Nano-1 also slightly surpassing Whisper. Both models support Mandarin, with Ultra expected to offer even greater audio processing capabilities.
-
-
Minimizing Hallucinations: Gemini models have undergone fine-tuning with custom supervised datasets and through RLHF to enhance specific behaviors:
- Attribution: Gemini is designed to generate responses that are closely aligned with the provided context, especially when instructions demand context-based responses.
- Closed-book Response Generation: In scenarios where prompts seek factual answers without specific sources, Gemini is tailored to avoid generating incorrect or hallucinated information.
- Avoidance: When faced with "unanswerable" prompts, Gemini opts for an avoidance strategy, refraining from generating hallucinations and indicating its inability to provide an answer.
- Results: There's a 50% reduction in inaccuracies in factuality tests, a 50% increase in attribution accuracy, and a jump from 0% to 70% in successful avoidance in relevant tests. However, these improvements haven't been benchmarked against GPT-4.
-
-
Pro Model
- Distinguished by its training efficiency, capable of completing its pre-training phase in just a few weeks.
-
Nano Variants
- Consists of two versions: Nano-1 with 1.8 billion parameters and Nano-2 with 3.25 billion.
- Both variants are refined versions distilled from larger Gemini models, featuring advanced 4-bit quantization. They set the standard in their category, particularly excelling in speech recognition, where they surpass the capabilities of Whisper.
This blog is a English translation of the original Chinese content, using GPT-4.